Select a Solution
Value Systems
Company
Resources
Capabilities
Technology Operations
For deal teams and operators who need repeatable technology reliability—not fire drills, delivery drag, security anxiety, and “tribal knowledge” operations.
Start here
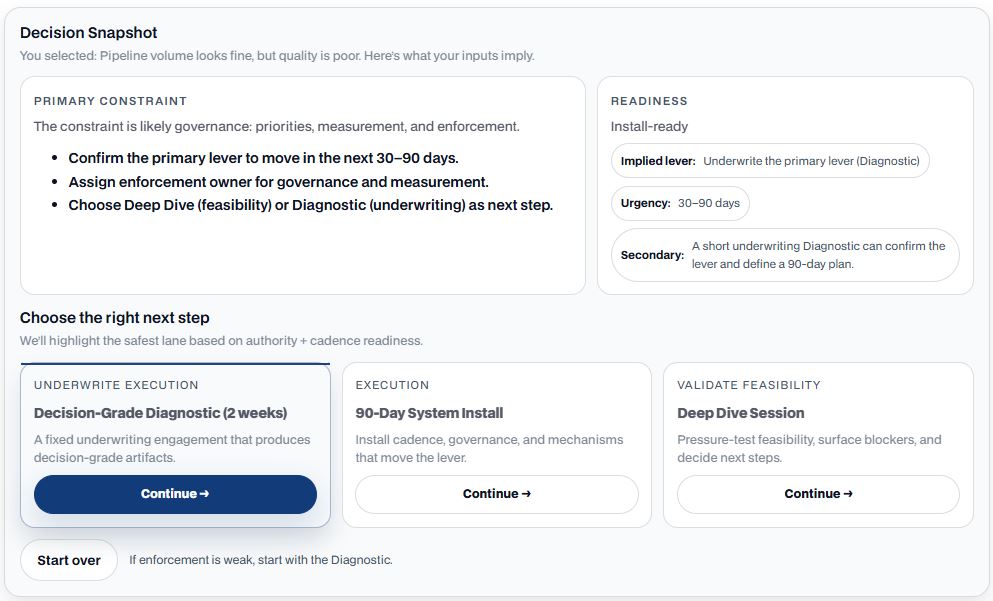
Make the risk + value case first—then decide what to harden.
+
TechOps is a system problem. If you can’t quantify impact and failure cost, fixes become tool shopping. Use the value model to anchor priorities, then map to the functional area responsible.
Defaults are conservative: the model treats reliability + delivery speed as measurable levers (downtime cost, productivity recovery, risk reduction).
Next
Follow the 3-step path
Start with the value model to quantify impact, then identify the highest-leverage TechOps area, then confirm evidence gates so reliability and delivery gains hold under scrutiny.
Run the Value Model (≈2 min)
Set baseline + improvement assumptions. See enterprise value impact instantly.
Identify the leverage area
Scan the functional grid. Open one area to see owners, metrics, maturity signals, and failure modes.
Check evidence gates
Confirm what must be true for reliability, security, and delivery improvements to hold.
Step 1 - Value Model
Simple 5-input model. For TechOps, margin improvement is a practical proxy for reliability gains and lower cost-to-serve: fewer incidents, less toil, better capacity efficiency, and tighter delivery control.
Start here
Calculator: impact on EV and equity value
+
Assumptions: EV = EBITDA × multiple. Δ Equity ≈ Δ EV + working capital release.
Tip: if you’re modeling uptime, incident reduction, infra efficiency, or delivery speed, express the combined impact as margin improvement (pp) to keep the model simple.
Step 2 - Leverage Areas
Scan the grid. Open one area to see ownership, core metrics, signals of maturity, and common failure modes.
Reliability & Incident Management
Step 3 - Evidence Gates (IC-safe)
If these aren’t true, reliability, delivery, and cost improvements won’t hold. Each gate should have an owner and a system-of-truth.
Proof gates
Pass/fail checkpoints that defend the case
+
- Clear owners per service (RACI) + on-call assignment.
- Runbooks exist for top incident classes.
- Dependencies and escalation paths are documented.
- Customer-facing SLOs defined for critical services.
- Error budget policy tied to release/feature decisions.
- SLO reporting is trusted and reviewed on cadence.
- Logs/metrics/traces cover critical paths (not best-effort).
- Alerting is actionable (low noise, clear owners).
- MTTD/MTTR tracked with root-cause categories.
- CI/CD health is measured (build success, rollback rate).
- Change failure rate is visible and owned.
- Safe deploy patterns exist (feature flags, canaries).
- Vulnerability scanning coverage is known and improving.
- Patch SLAs by severity + tracked MTTR.
- Access controls and secrets handling are audited.
- Unit cost defined (per request/tenant/workload).
- Budgets/alerts + anomaly detection for spend.
- Capacity planning exists for peak + growth scenarios.
TechOps overview
Reliability → Delivery → What “good” looks like
Three quick expanders: what breaks today, what changes when you install TechOps governance, and the maturity signals that hold under scrutiny.
What TechOps fixes
Incidents, delivery drag, and brittle systems-of-truth.
When ownership and controls are weak, reliability becomes reactive and delivery becomes churn.
Mature TechOps installs governance so uptime, change, and cost are measurable—not heroic.
+
When ownership and controls are weak, reliability becomes reactive and delivery becomes churn. Mature TechOps installs governance so uptime, change, and cost are measurable—not heroic.
Reliability governance
Make reliability inspectable with SLOs and error budgets.
- SLOs per critical service (written + owned)
- Error budgets drive release decisions
- Postmortems yield tracked action items
Change control
Reduce change failure rate without freezing delivery.
- Standard release paths + approvals for exceptions
- Rollback/runbook readiness enforced
- Change windows and blast radius controls
Incident operations
Shorten detection-to-recovery with clear roles and signals.
- On-call roles, escalation paths, and comms templates
- Alert quality: fewer false pages, higher signal
- MTTA/MTTR tracked by service
Platform standards
Reduce bespoke work with golden paths and paved roads.
- Reference architectures + reusable templates
- Service ownership + dependency mapping
- Standard observability and logging baseline
Cost governance
Stop cloud cost drift with allocation and guardrails.
- Tagging/chargeback mapped to owners
- Budget alerts + anomaly detection
- Unit economics tracked (cost per txn/user)
Data & access controls
Reduce security and compliance risk with enforceable policy.
- Least-privilege access with periodic reviews
- Secrets management + audit trails
- Data classification and retention rules
Practical rule: if service ownership + operational controls aren’t explicit, reliability and delivery won’t hold under scrutiny.
What you get
A governed operating system for reliability, delivery, and cost.
Concrete mechanisms that hold under scrutiny—SLOs, change controls, incident rigor, and ownership you can run weekly (not tribal knowledge).
+
Concrete mechanisms that hold under scrutiny—SLOs, change controls, incident rigor, and ownership you can run weekly (not tribal knowledge).
Service ownership + SLOs
Make uptime and user experience measurable—by service, by owner.
- SLOs + error budgets per critical path
- Ownership map (who owns what, 24/7)
- Dependencies visible (services, vendors, data)
Incident operating model
Reduce detection-to-recovery with clear roles, signals, and comms.
- On-call rotations + escalation paths
- Postmortems with tracked remediation
- MTTA/MTTR dashboards by service
Change + release governance
Ship faster with fewer regressions—without “freeze culture.”
- Standard release paths + exception approvals
- Change risk controls (blast radius, rollbacks)
- Change failure rate tracked over time
Cost + risk controls
Stop cost drift and reduce security exposure with enforceable policy.
- Cost allocation to owners (tags / chargeback)
- Anomaly alerts + budget guardrails
- Access + secrets hygiene with audit trails
Outcome: operations you can measure, operate, and defend—reliability and delivery without heroics.
What maturity looks like
What “good” looks like in a TechOps model
Use this as a quick diagnosis: the upside is measurable, but maturity usually fails on ownership, SLOs, and change control—not tools.
+
Use this as a quick diagnosis: the upside is measurable, but maturity usually fails on ownership, SLOs, and change control—not tools.
Benefits
What improves when you level up
- Fewer incidents when services have owners, SLOs, and error budgets.
- Faster delivery with safer releases and lower change failure rate.
- Lower toil by fixing alert noise, automating runbooks, and eliminating manual rework.
- Predictable capacity via demand signals, dependency visibility, and sane prioritization.
- Cost and risk controlled when spend and access are owned and audited.
Obstacles
What usually blocks maturity
- No clear ownership: services, pipelines, and platforms lack accountable operators.
- Undefined reliability targets: uptime and performance are debated, not governed (no SLOs).
- Alert fatigue: noisy monitoring hides the real failures and slows response.
- Release chaos: manual approvals, missing rollbacks, and inconsistent change practices.
- Tool sprawl: overlapping platforms and brittle integrations create “where is the truth?” debates.
Practical rule: if ownership + SLOs + change control aren’t owned, improvements won’t hold under scrutiny.
AI capabilities
AI-Driven Technology Operations
Technology Ops AI should reduce toil, improve reliability, and tighten governance. These capabilities emphasize
human-in-the-loop approvals, change control, and evidence trails
so leaders can ship faster without increasing risk.
-
Governance First
-
Workflow-Native
-
Measurable Outcomes
-
Secure + Compliant
-
Explainable AI
-
Fast to Deploy
+
AI capabilities
AI-Driven Technology Operations
Technology Ops AI should reduce toil, improve reliability, and tighten governance. These capabilities emphasize human-in-the-loop approvals, change control, and evidence trails so leaders can ship faster without increasing risk.
- Governance First
- Workflow-Native
- Measurable Outcomes
- Secure + Compliant
- Explainable AI
- Fast to Deploy
Incident Triage & Response Assist
ReliabilityReduce MTTR by drafting diagnostics, correlating signals, and routing the right responders—while keeping approvals explicit.
- Alert clustering and likely-cause hypotheses from logs/metrics/traces
- Runbook recommendations with confidence bands + required human checks
- Post-incident drafts (timeline, impact, actions, owners)
Assistive by design—not autonomous remediation.
See fitChange Risk Scoring & Release Guardrails
Change controlPrevent high-risk releases from slipping into production unnoticed by adding gates, checks, and approval paths.
- Risk scoring by blast radius, dependency touch, and rollback complexity
- Pre-flight checks and “go/no-go” prompts tied to evidence
- Approval workflows for risky services, windows, and customer-impact changes
Turns deployment into a controlled decision.
See fitBacklog Hygiene & PRD/Spec Drafting
DeliveryKeep product and engineering aligned by standardizing requirements and keeping tickets “ready” before they hit sprint planning.
- Ticket normalization (acceptance criteria, dependencies, edge cases)
- PRD/spec drafts from stakeholder inputs and prior patterns
- Scope & risk flags to prevent stealth complexity
Reduces rework and sprint churn.
See fitKnowledge Base & Runbook Maintenance
SOPsKeep runbooks current by drafting updates after incidents, releases, and architecture changes—so docs reflect reality.
- Runbook drafts from actual resolution steps and tooling
- “What changed” notes after releases and infra migrations
- Context surfacing during incidents (links, owners, known issues)
Cuts tribal knowledge risk.
See fitSecurity & Compliance Assist
GovernanceSpeed up security work without weakening controls: classify findings, draft evidence, and route approvals with a clear audit trail.
- Finding triage (severity, exploitability, scope) with evidence links
- Control evidence packs (SOC2/ISO-style artifacts) drafted for review
- Exception handling with time-boxed waivers and owners
Optimizes for “audit-ready” proof.
See fitService Ownership, SLOs & Early Warning Signals
SignalsDetect reliability drift early and route it into your operating rhythm—so the team fixes root causes before customers notice.
- SLO tracking with burn-rate alerts and owner escalation
- Reliability briefs that summarize “what changed” with evidence
- Backlog routing into weekly cadence and decision gates
Pairs with a weekly reliability review.
See fit